
Tidying Data 🧹
MATH/COSC 3570 Introduction to Data Science
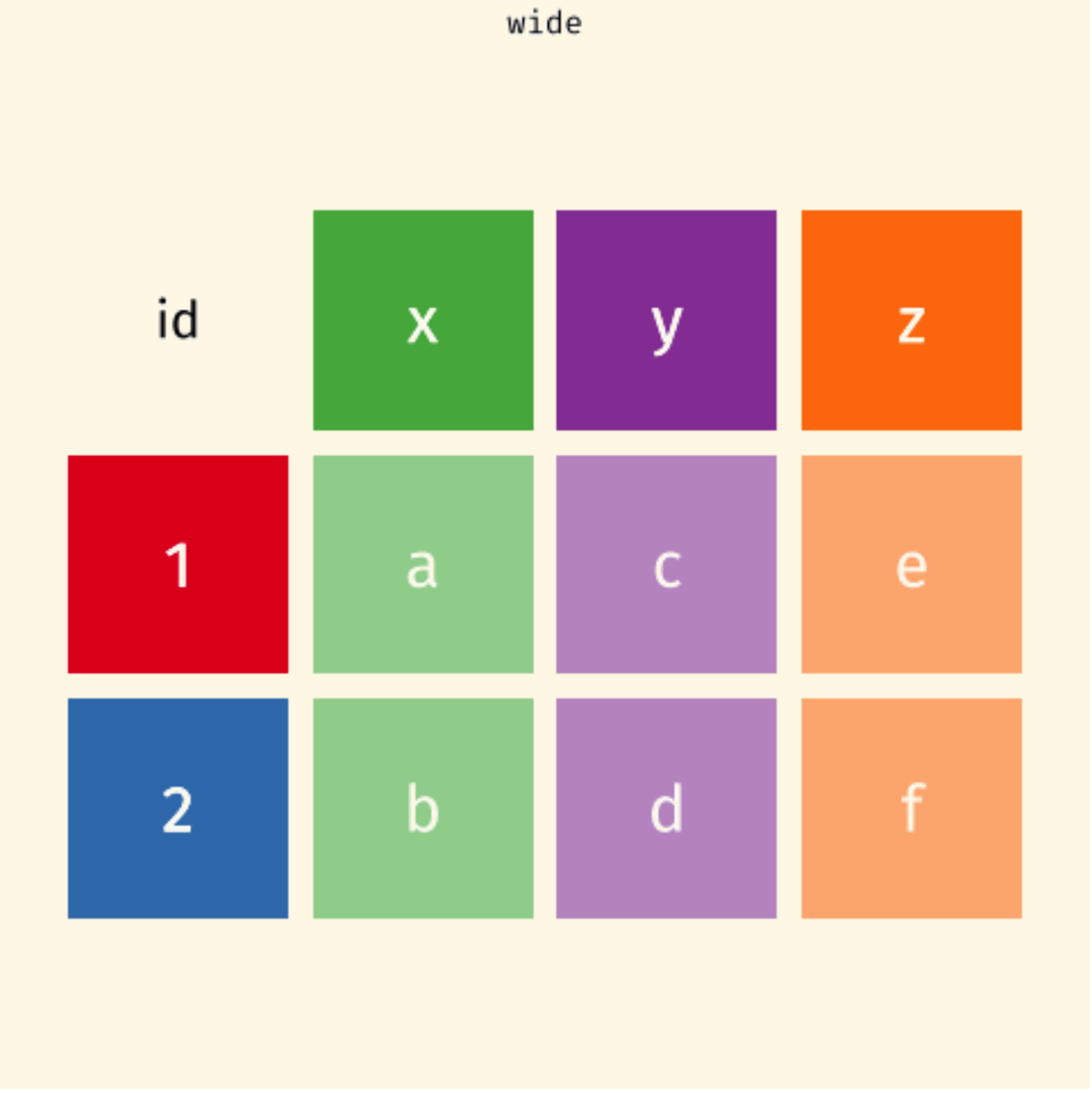
Wide Data
To tidy your data, (1) figure out what the (column) variables and (row) observations are; (2) resolve one of two common problems:
One (column) variable spreads across multiple columns
customers <- read_csv("./data/sales/customers.csv")wider (\(2 \times 4\))
more columns than we want!
customers# A tibble: 2 × 4
customer_id item_1 item_2 item_3
<dbl> <chr> <chr> <chr>
1 1 bread milk banana
2 2 milk toilet paper <NA> - We may want one single column variable
itemshowing all purchased times.
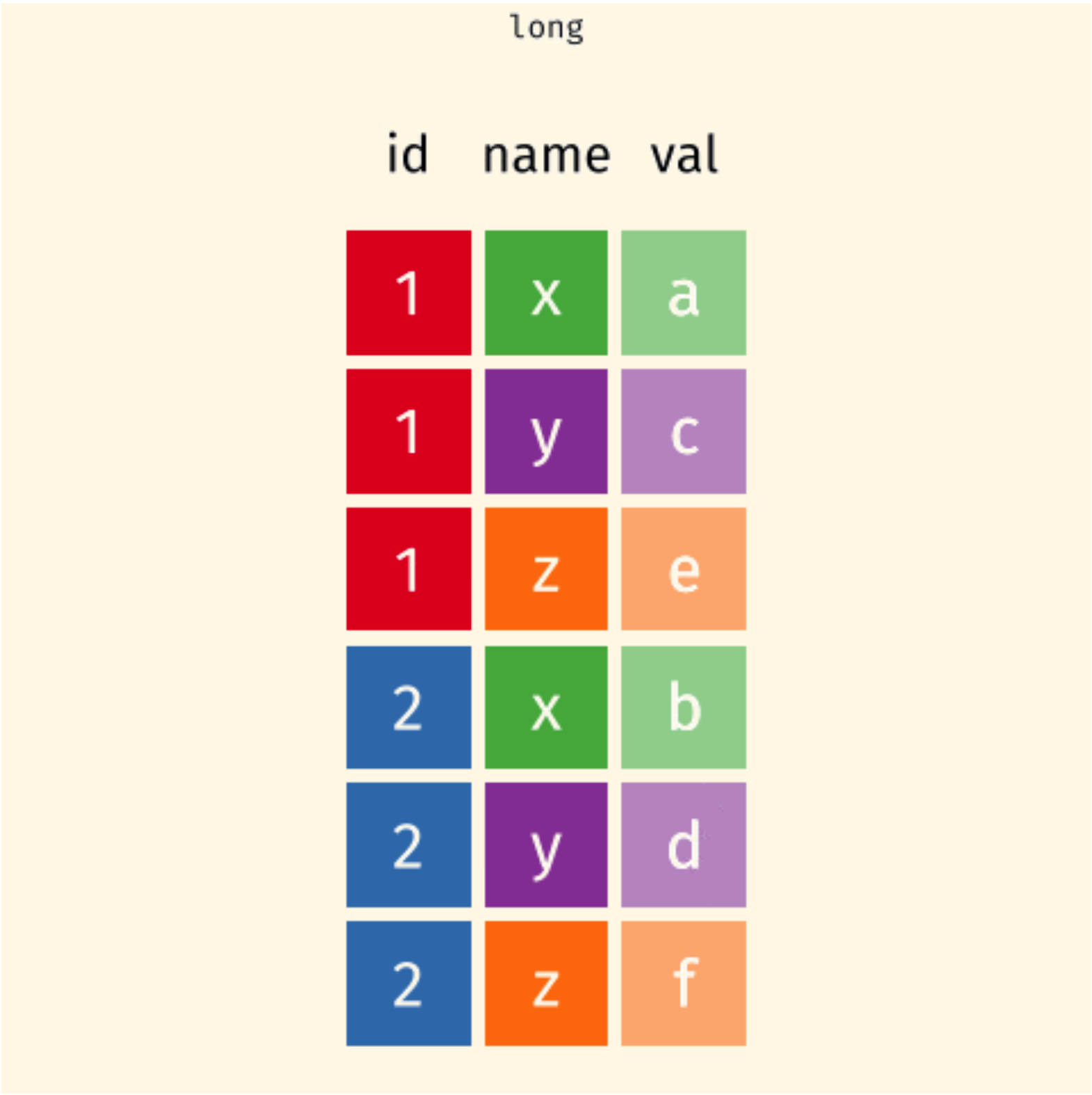
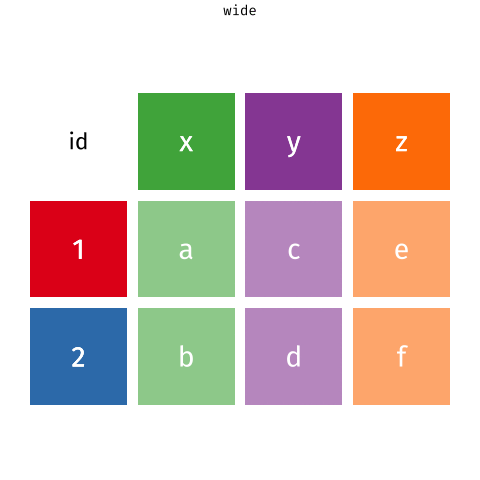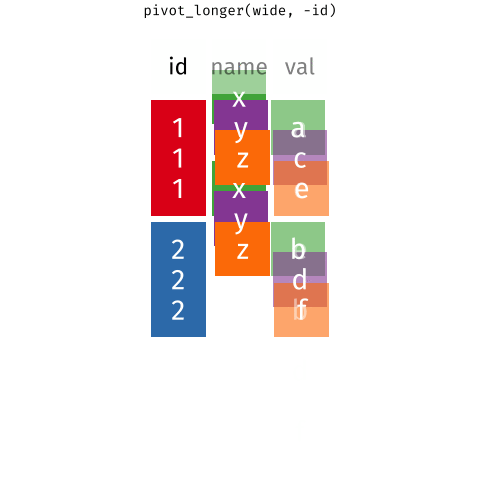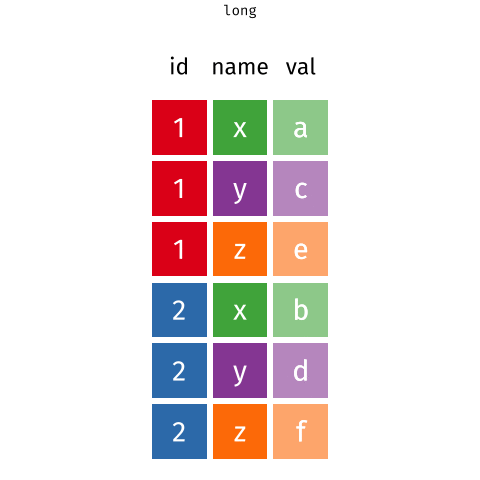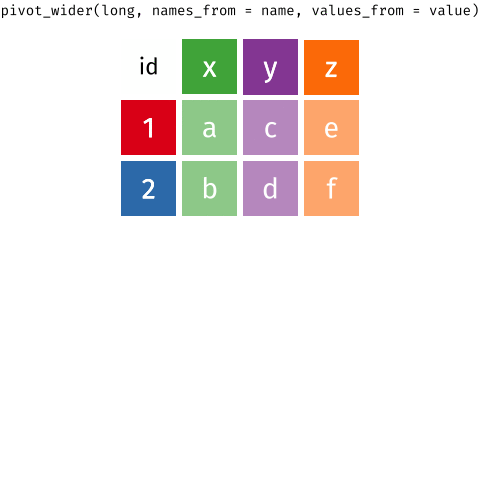
Long Data
One (row) subject is scattered across multiple rows
longer (\(6 \times 3\))
more rows than we want!
# A tibble: 6 × 3
customer_id item_no item
<dbl> <chr> <chr>
1 1 item_1 bread
2 1 item_2 milk
3 1 item_3 banana
4 2 item_1 milk
5 2 item_2 toilet paper
6 2 item_3 <NA> We may want each row corresponds to one single customer, not one single purchased item.
Which data format we adopt depends on our own research question.
pivot_longer() and pivot_wider()
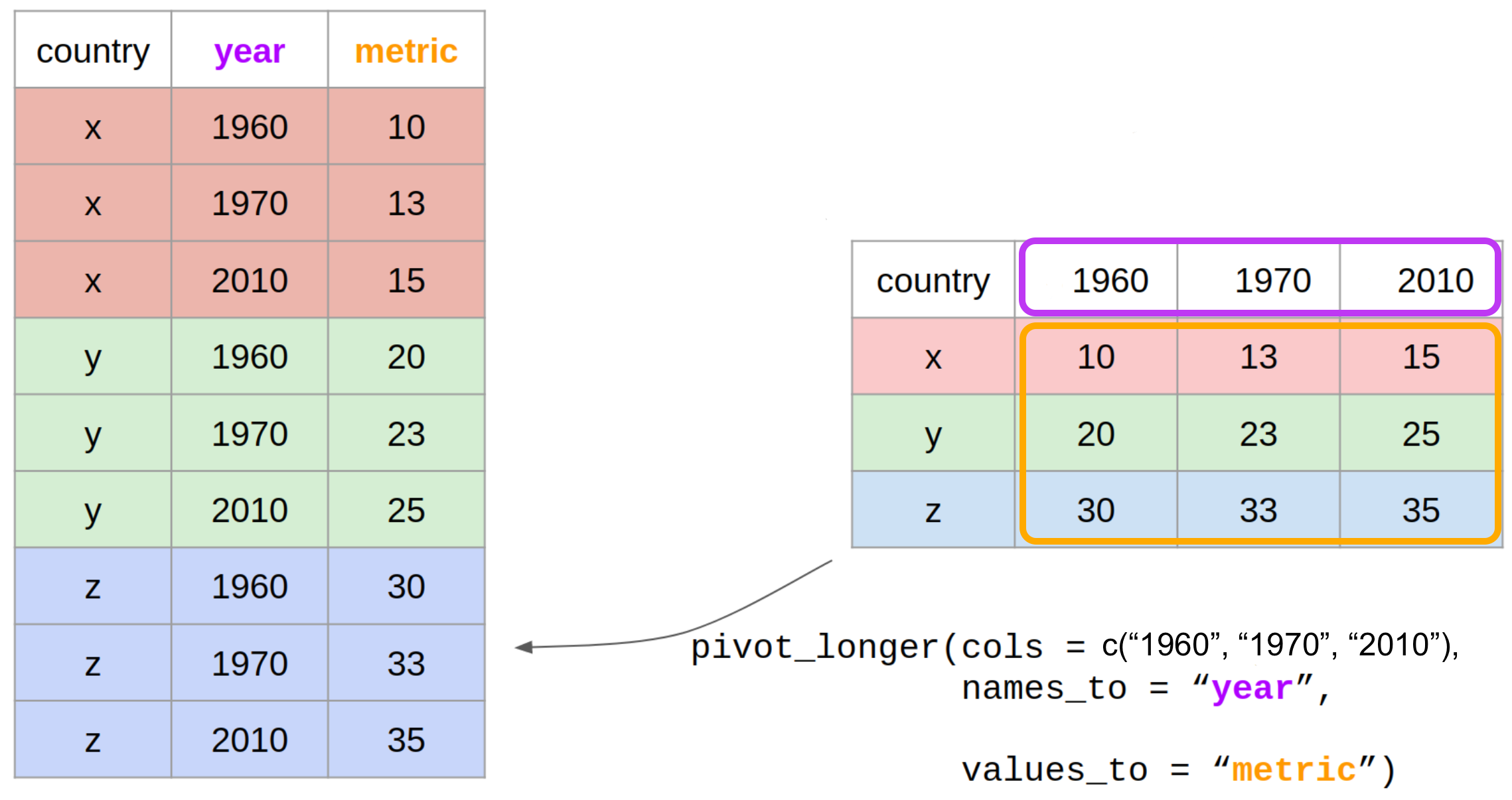
pivot_longer()
data: data framecols: columns to pivot into longer format (1960, 1970, 2010)
pivot_longer()
-
names_to: name of the column where column names of pivoted variables go (year)
pivot_longer()
-
values_to: name of the column where data values in pivoted variables go (metric)
pivot_wider()
data: data framenames_from: which column variable in the long format contains the what should be column names in the wide format (year)
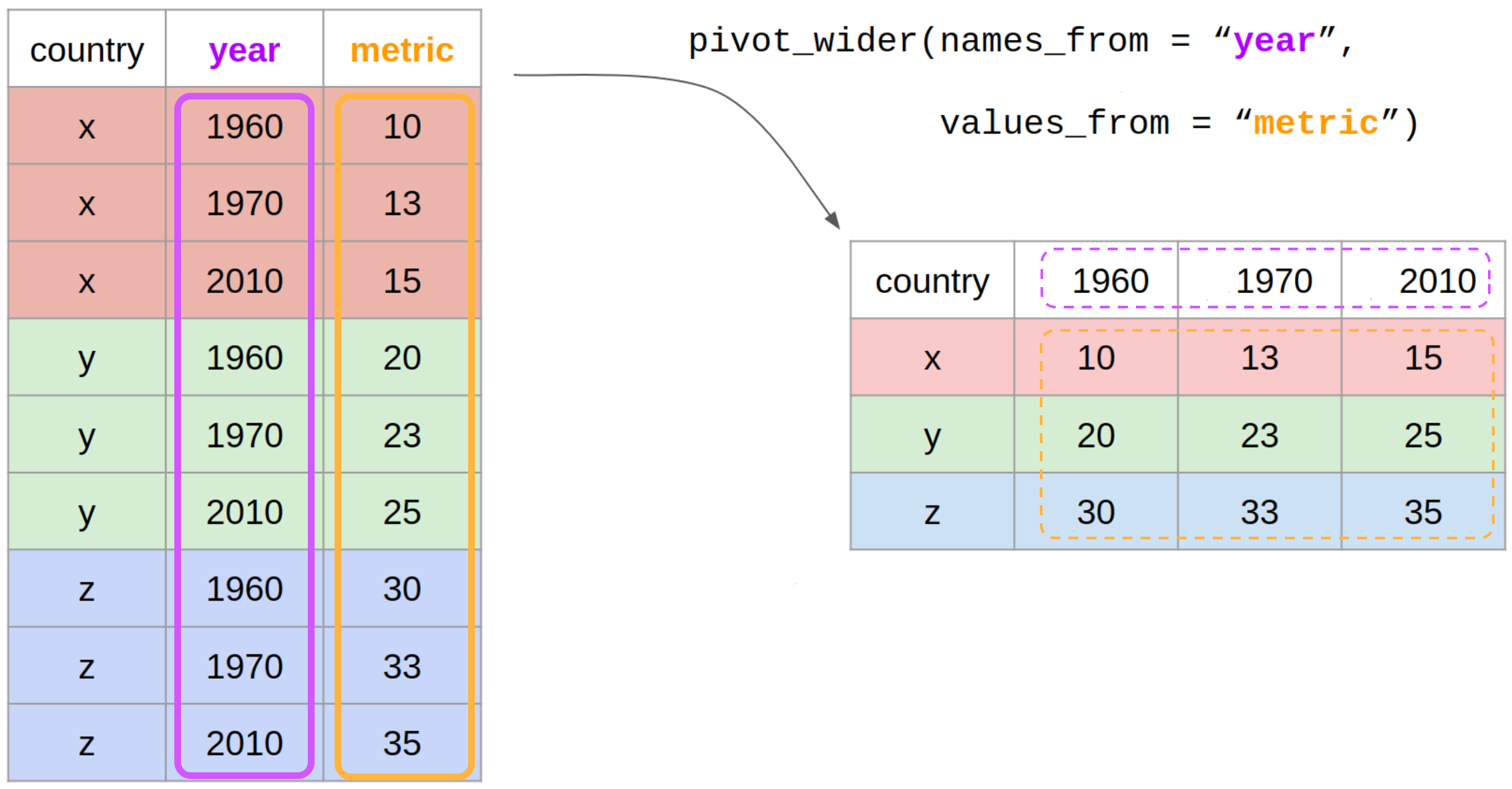
pivot_wider()
data: data framevalues_from: which column variable in the long format contains the what should be values in the new columns in the wide format (metric)
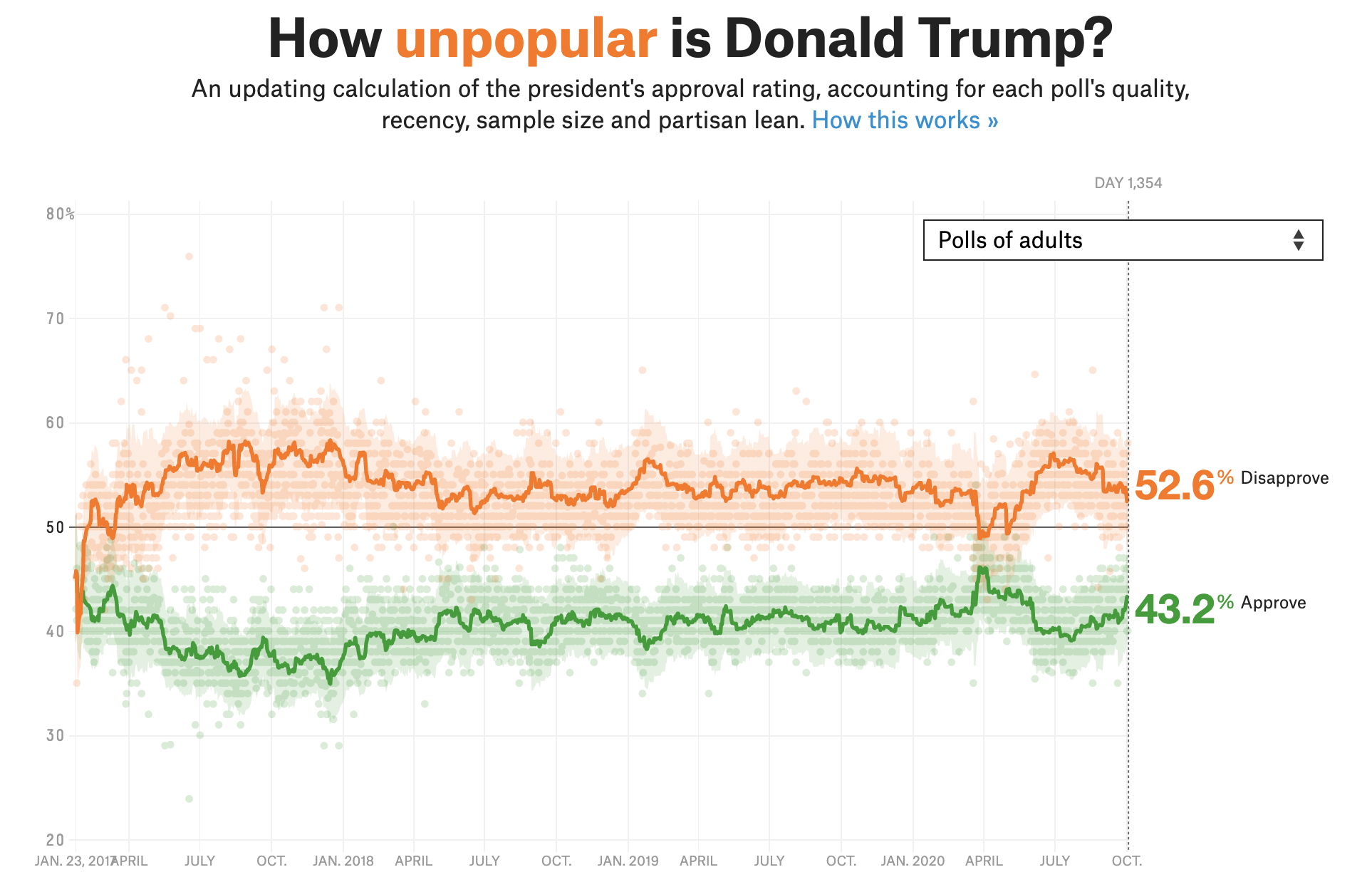
BONUS 💷: Use trump_longer to generate a plot like the one below.
pd.pivot()
purchases customer_id item_no item
0 1 item_1 bread
1 2 item_1 milk
2 1 item_2 milk
3 2 item_2 toilet paper
4 1 item_3 banana
5 2 item_3 NaNpurchases.pivot(index = "customer_id", columns = "item_no", values = "item")item_no item_1 item_2 item_3
customer_id
1 bread milk banana
2 milk toilet paper NaN![]()