Basic R and Python
MATH/COSC 3570 Introduction to Data Science
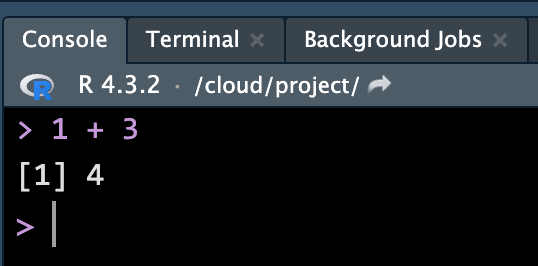
Run Code in Console
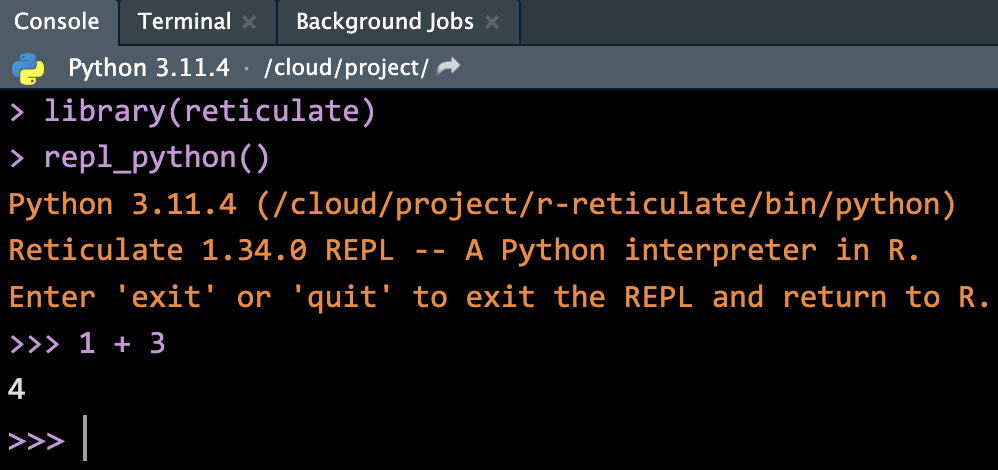
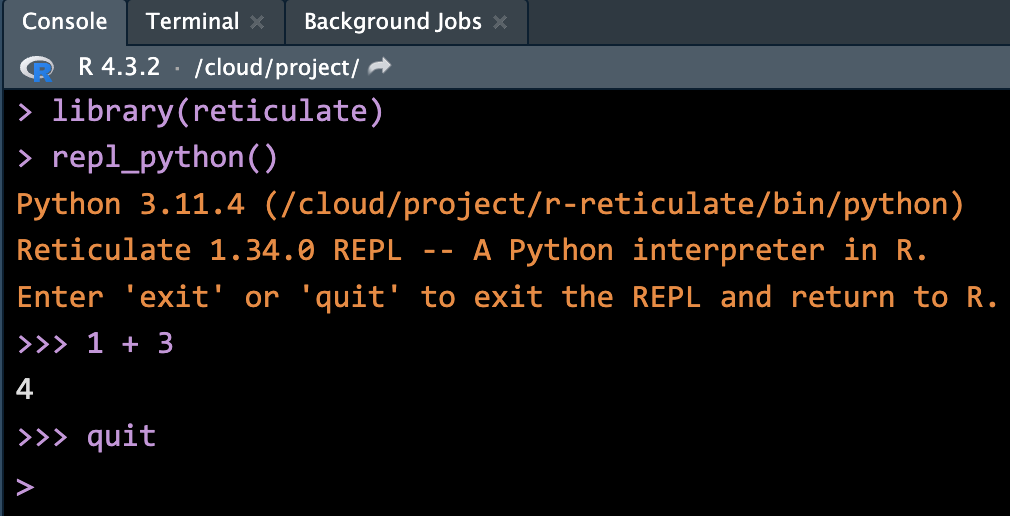
-
quitorexitto switch back to R.
Arithmetic and Logical Operators

2 + 3 / (5 * 4) ^ 2[1] 2.015 == 5.00[1] TRUE# 5 and 5L are of the same value too
# 5 is of type double; 5L is integer
5 == 5L[1] TRUEtypeof(5L)[1] "integer"!TRUE == FALSE[1] TRUE![]()
2 + 3 / (5 * 4) ** 22.00755 == 5.00True5 == int(5)Truetype(int(5))<class 'int'>not True == FalseTrueArithmetic and Logical Operators
Math Functions
Math functions in R are built-in.
# R comment![]()
Need to import math library in Python.
import math
math.sqrt(144)12.0math.exp(1)2.718281828459045math.sin(math.pi/2)1.0math.log(32, 2)5.0abs(-7)7# python comment

Variables and Assignment
Object Types
character, double, integer and logical.
typeof(5)[1] "double"typeof(5L)[1] "integer"typeof("I_love_data_science!")[1] "character"typeof(1 > 3)[1] "logical"is.double(5L)[1] FALSE![]()
str, float, int and bool.
type(5.0)<class 'float'>type(5)<class 'int'>type("I_love_data_science!")<class 'str'>type(1 > 3)<class 'bool'>type(5) is floatFalse

- Variable defined previously is a scalar value, or in fact a (atomic) vector of length one.
List (Generic Vectors)
Lists are different from (atomic) vectors: Elements can be of any type, including lists.
Construct a list by using
list().

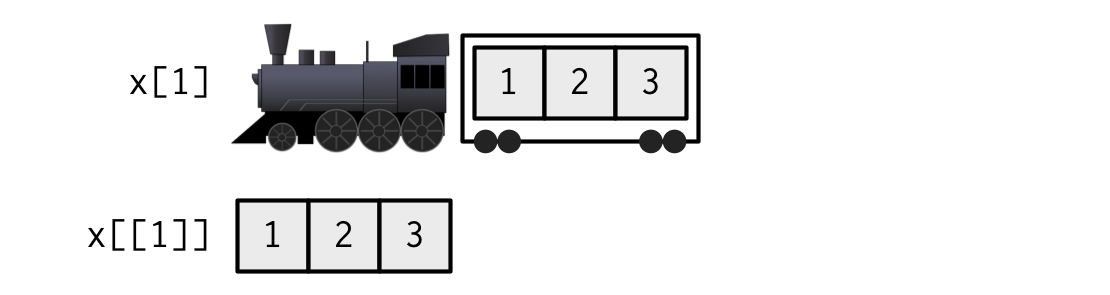
If list
xis a train carrying objects, thenx[[5]]is the object in car 5;x[4:6]is a train of cars 4-6.— @RLangTip, https://twitter.com/RLangTip/status/268375867468681216

Python Data Structures for Data Science
Python built-in data structures are not specifically for data science.
To use more data science friendly functions and structures, such as array or data frame, Python relies on packages
NumPyandpandas.
![]()
![]()
Installing NumPy and pandas*
In your lab-yourusername project, run
library(reticulate)
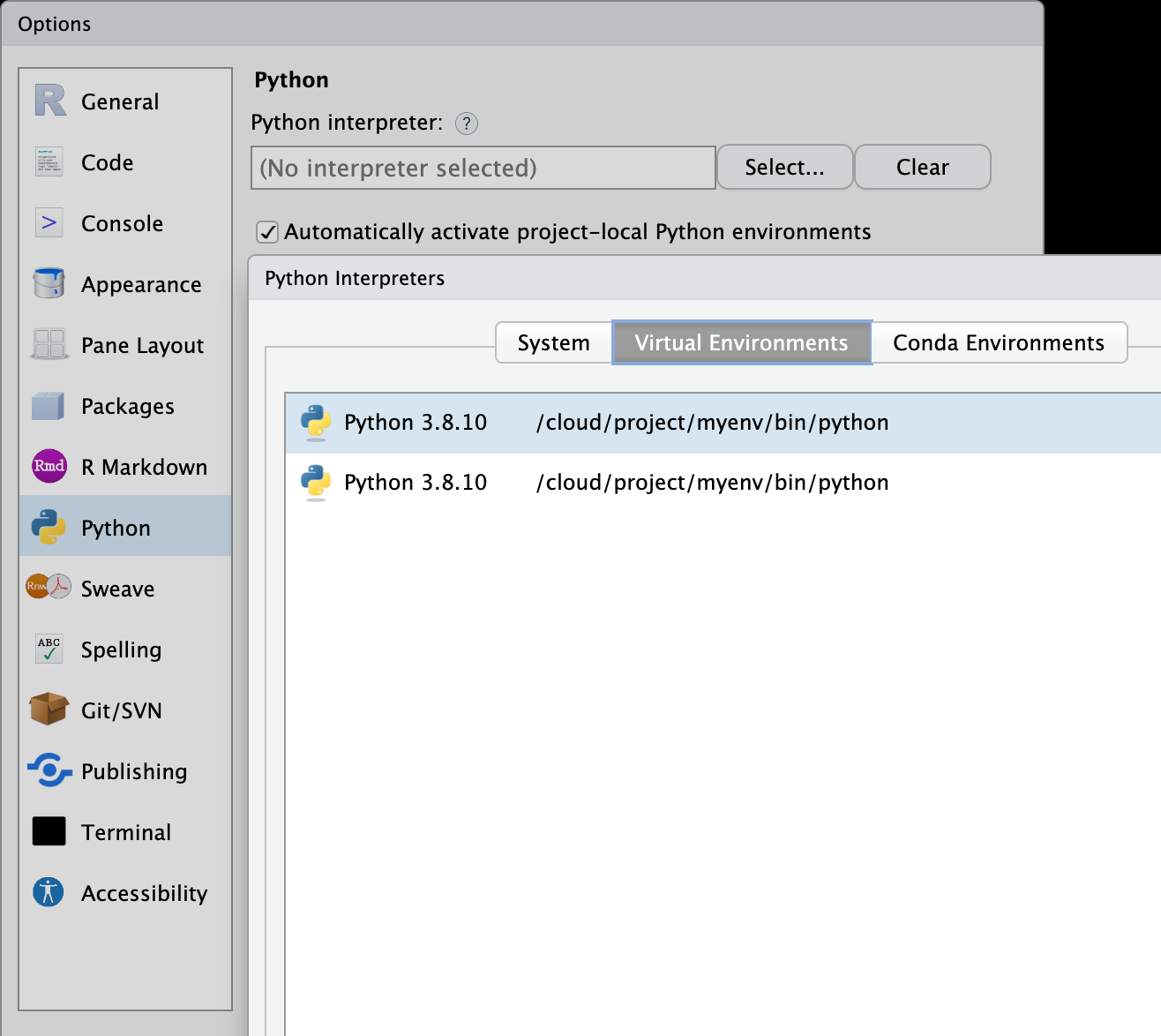
virtualenv_create("myenv")Go to Tools > Global Options > Python > Select > Virtual Environments
Central Tendency: Mean and Median
Variation
summary(data) Min. 1st Qu. Median Mean 3rd Qu. Max.
3.0 9.8 17.0 55.3 47.5 230.0 ![]()
np.quantile(data, [0.25, 0.5, 0.75])array([ 9.75, 17. , 47.5 ])np.var(data, ddof = 1)7676.666666666666np.std(data, ddof = 1)87.61658899242008df = pd.Series(data)
df.describe()count 6.000000
mean 55.333333
std 87.616589
min 3.000000
25% 9.750000
50% 17.000000
75% 47.500000
max 230.000000
dtype: float64R plot()
mtcars[1:15, 1:4] mpg cyl disp hp
Mazda RX4 21.0 6 160 110
Mazda RX4 Wag 21.0 6 160 110
Datsun 710 22.8 4 108 93
Hornet 4 Drive 21.4 6 258 110
Hornet Sportabout 18.7 8 360 175
Valiant 18.1 6 225 105
Duster 360 14.3 8 360 245
Merc 240D 24.4 4 147 62
Merc 230 22.8 4 141 95
Merc 280 19.2 6 168 123
Merc 280C 17.8 6 168 123
Merc 450SE 16.4 8 276 180
Merc 450SL 17.3 8 276 180
Merc 450SLC 15.2 8 276 180
Cadillac Fleetwood 10.4 8 472 205plot(x = mtcars$mpg, y = mtcars$hp,
xlab = "Miles per gallon",
ylab = "Horsepower",
main = "Scatter plot",
col = "red",
pch = 5, las = 1)
Argument pch
- The defualt is pch = 1
Python matplotlib.pyplot
Code
mtcars = pd.read_csv('./data/mtcars.csv')
mtcars.iloc[0:15,0:4] mpg cyl disp hp
0 21.0 6 160.0 110
1 21.0 6 160.0 110
2 22.8 4 108.0 93
3 21.4 6 258.0 110
4 18.7 8 360.0 175
5 18.1 6 225.0 105
6 14.3 8 360.0 245
7 24.4 4 146.7 62
8 22.8 4 140.8 95
9 19.2 6 167.6 123
10 17.8 6 167.6 123
11 16.4 8 275.8 180
12 17.3 8 275.8 180
13 15.2 8 275.8 180
14 10.4 8 472.0 205import matplotlib.pyplot as plt
plt.scatter(x = mtcars.mpg,
y = mtcars.hp,
color = "r")
plt.xlabel("Miles per gallon")
plt.ylabel("Horsepower")
plt.title("Scatter plot")
R Subplots
Python Subplots
The command
plt.scatter()is used for creating one single plot.If multiple subplots are wanted in one single call, one can use
plt.subplots()
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.scatter(x = mtcars.mpg, y = mtcars.hp)
ax2.scatter(x = mtcars.mpg, y = mtcars.wt)
ax1.set_xlabel("mpg")
ax2.set_xlabel("mpg")
R boxplot()
Python boxplot()
Code
cyl_num = np.unique(mtcars.cyl)
cyl_list = []
cyl_list.append(mtcars[mtcars.cyl == cyl_num[0]].mpg)
cyl_list.append(mtcars[mtcars.cyl == cyl_num[1]].mpg)
cyl_list.append(mtcars[mtcars.cyl == cyl_num[2]].mpg)import matplotlib.pyplot as plt
plt.boxplot(cyl_list, vert=False, tick_labels=[4, 6, 8])plt.xlabel("Miles per gallon")
plt.ylabel("Number of cylinders")
R hist()
-
hist()decides the class intervals/with based onbreaks. If not provided, R chooses one.
hist(mtcars$wt,
breaks = 20,
col = "#003366",
border = "#FFCC00",
xlab = "weights",
main = "Histogram of weights",
las = 1)
Python hist()
## by default bins=10
plt.hist(mtcars.wt,
bins = 20,
color="#003366",
edgecolor="#FFCC00")
plt.xlabel("weights")
plt.title("Histogram of weights")
R barplot()
(counts <- table(mtcars$gear))
3 4 5
15 12 5 
Python barplot()
count_py = mtcars.value_counts('gear')
count_pygear
3 15
4 12
5 5
Name: count, dtype: int64plt.bar(["3", "4", "5"], count_py)
plt.xlabel("Number of Gears")
plt.title("Car Distribution")
R pie()
3 4 5
46.9 37.5 15.6 (labels <- paste0(3:5, " gears: ", percent, "%"))[1] "3 gears: 46.88%" "4 gears: 37.5%" "5 gears: 15.62%"pie(x = counts, labels = labels,
main = "Pie Chart",
col = 2:4,
radius = 1)
Python pie()
percent = round(count_py / sum(count_py) * 100, 2)
texts = (percent.index.astype(str) + " gears: " + percent.astype(str) + "%").tolist()plt.pie(count_py, labels = texts, colors = ['r', 'g', 'b'])plt.title("Pie Charts")
R 2D Imaging: image()
- The
image()function displays the values in a matrix using color.
In Python,
Code
matrix = np.arange(1, 31).reshape(5, 6)
plt.imshow(matrix, cmap="viridis", origin="lower")
plt.colorbar()
plt.show()R fields::image.plot()
num [1:87, 1:61] 100 101 102 103 104 105 105 106 107 108 ...image.plot(volcano) num [1:87, 1:61] 100 101 102 103 104 105 105 106 107 108 ...
R 2D Imaging Example: Volcano
R 3D scatter plot: scatterplot3d()
library(scatterplot3d)
scatterplot3d(x = mtcars$wt,
y = mtcars$disp,
z = mtcars$mpg,
main = "3D Scatter Plot",
xlab = "Weights",
ylab = "Displacement",
zlab = "Miles per gallon",
pch = 16,
color = "steelblue")
In Python,
Code
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.scatter(mtcars['wt'], mtcars['disp'], mtcars['mpg'], c='steelblue', marker='o')
ax.set_title("3D Scatter Plot")
ax.set_xlabel("Weights")
ax.set_ylabel("Displacement")
ax.set_zlabel("Miles per gallon")
plt.show()R Perspective Plot: persp()
par(mar = c(0,0,0,0))
# Exaggerate the relief
z <- 2 * volcano
# 10 meter spacing (S to N)
x <- 10 * (1:nrow(z))
# 10 meter spacing (E to W)
y <- 10 * (1:ncol(z))
par(bg = "slategray")
persp(x, y, z, theta = 135, phi = 30,
col = "green3", scale = FALSE,
ltheta = -120, shade = 0.75,
border = NA, box = FALSE)
In Python,
Code
volcano = pd.read_csv("./slides/data/volcano.csv", index_col=0)
volcano = volcano.values
z = 2 * volcano
x = np.arange(1, z.shape[0] + 1) * 10
y = np.arange(1, z.shape[1] + 1) * 10
X, Y = np.meshgrid(y, x)
fig = plt.figure()
ax = fig.add_subplot(projection='3d', facecolor="slategray")
ax.plot_surface(X, Y, z, cmap="Greens", edgecolor="none", shade=True, alpha=0.9)
plt.show()Resources
We will talk about data visualization in detail soon!
![]()